任务背景
在大语言模型的应用过程中,有许多问题是类似的,而他们的答案也是极为相近的。这与计算机的局部性原理有异曲同工之妙。由此可引出大语言的模型的缓存——通过向量相似度检索问题,找到对应回答过的答案。
使用缓存的优势:
1.节约调用模型的成本,不论是使用 api 调用的经济成本还是部署的推理成本。 2.提高响应速度。 3.稳定性保障,接受到大量请求时能有效响应。
所以个人认为模型缓存 在对结果不那么敏感,且对成本要求或响应速度要求严格的场景很大的应用空间。
技术选型
当你遇到一个技术上可行的好点子,大概率已经有人做过了,在互联网上寻找类似的开源解决方案。主要包括 GPTCache 和在此基础上二次开发的 ModelCache。
开源方案 -GPTCache
zilliztech/GPTCache: Semantic cache for LLMs. Fully integrated with LangChain and llama_index.
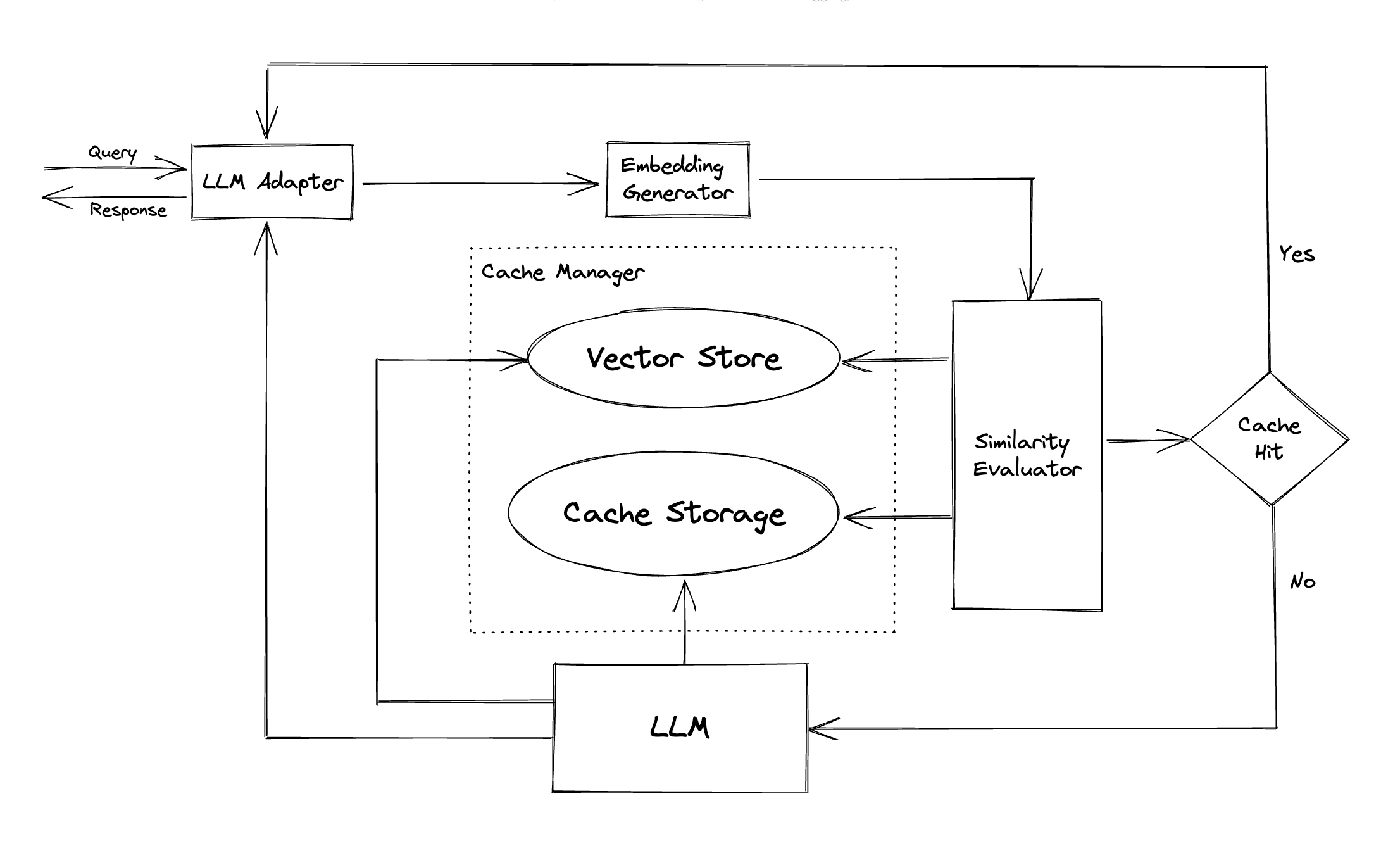
GPTCache 目前支持两种 LLM 适配器:OpenAI 和 Langchain。 根据其官方文档,使用 langchain 标准接口连接 LLMs,并使用 GPTCache 进行缓存的代码如下:
import time
def response_text(openai_resp):
return openai_resp['choices'][0]['message']['content']
print("Cache loading.....")
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache.adapter import openai
cache.init()
cache.set_openai_key()
# -------------------------------------------------
question = "what's github"
for _ in range(2):
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
'role': 'user',
'content': question
}
],
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')
output:
Cache loading.....
Question: what's github
Time consuming: 6.04s
Answer: GitHub is an online platform ...
Question: what's github
Time consuming: 0.00s
Answer: GitHub is an online platform ...
技术原理
调用 openai.ChatCompletion.create 时,函数内部调用 gptcache\core.py 中定义的 cache。实现在 create 中,将查询结果存入缓存与查询
在 adapter 中,实现 create 函数
@classmethod
def create(cls, *args, **kwargs):
chat_cache = kwargs.get("cache_obj", cache)
enable_token_counter = chat_cache.config.enable_token_counter # 是否启用token计数器。
def cache_data_convert(cache_data):
if enable_token_counter:
input_token = _num_tokens_from_messages(kwargs.get("messages"))
output_token = token_counter(cache_data)
saved_token = [input_token, output_token]
else:
saved_token = [0, 0]
if kwargs.get("stream", False):
return _construct_stream_resp_from_cache(cache_data, saved_token)
return _construct_resp_from_cache(cache_data, saved_token)
kwargs = cls.fill_base_args(**kwargs) # Fill the base args to the cache args
return adapt(
cls._llm_handler, # 处理OpenAI请求。
cache_data_convert, # 将OpenAI响应转换为缓存对象。
cls._update_cache_callback, # 在获取到OpenAI响应后更新缓存。
*args,
**kwargs, # 传递给cls._llm_handler的参数。
)
最后的 return adapt 实现流程的串联
adapt 函数的实现:
def adapt(llm_handler, cache_data_convert, update_cache_callback, *args, **kwargs):
llm_handler: 当缓存未命中时调用的服务或函数,用于实时请求数据。cache_data_convert: 当缓存命中时,将缓存中的数据转换为 LLM 返回格式的函数。update_cache_callback: 当缓存未命中,获取新数据后,用于更新缓存的回调函数。args: 传递给 LLM 的参数。kwargs: 传递给 LLM 的关键字参数。return: llm result
逻辑流程
- 初始化和配置加载:加载配置,处理一些前期参数配置如温度调控、缓存开启/跳过等。
- 数据预处理:如果配置了预处理步骤,对传入数据进行必要的转换和处理。
- 缓存查找与评估:
- 如果启用了缓存并决定不跳过,会根据预处理后的数据进行缓存查找。
- 对于查找到的每条缓存数据,进行健康检查和相似度评估。
- 满足相似度阈值的缓存数据会被选用。
- 后处理:
- 如果有有效的缓存回答,将通过后处理函数格式化最终输出。
- 如果有会话管理逻辑,处理会话相关数据。
- 缓存更新:
- 如果未命中缓存且启用了缓存,调用外部服务获取数据后,用给定的更新函数更新缓存。
所以,缓存与 LLM 服务未解耦时,先发动对 llm 的查询,在 adapt 过程中进行缓存查找
可以发现,GPTCache 与 LLM 之间是耦合的,这在实际开发和部署中颇为不便,我们更需要能独立开发的模型缓存,并将其部署到另一个单独项目中。
一番寻找,定位到阿里基于 GPTCache 二次开发的 ModelCache。
开源方案 -ModelCache
项目结构如下:
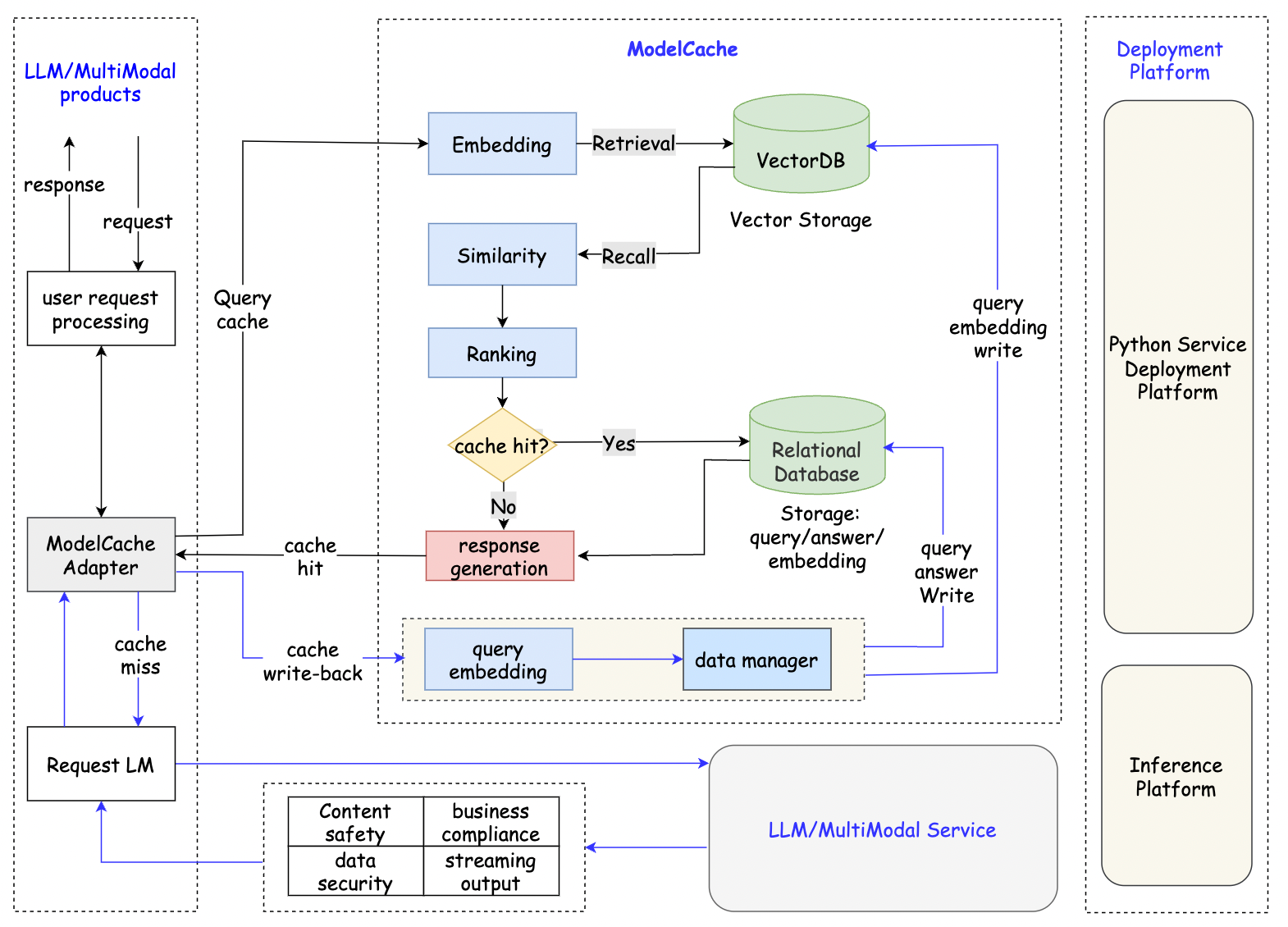
可以从结构图中看到,ModelCache 整个项目是从 LLM 的服务中抽离出来的,通过请求 api 来和 LLM 服务保持通信。
并且,ModelCache 具有不少其他优势,包括支持多轮回话,清空缓存,定制化的缓存驱逐策略。
ModelCache 与 LLM 服务交互的核心 api 包括三个:缓存写入,缓存查询,缓存清除
Cache-Writing
import json
import requests
url = 'http://127.0.0.1:5000/modelcache'
type = 'insert'
scope = {"model": "CODEGPT-1008"}
chat_info = [{"query": [{"role": "system", "content": "You are an AI code assistant and you must provide neutral and harmless answers to help users solve code-related problems."}, {"role": "user", "content": "你是谁?"}],
"answer": "Hello, I am an intelligent assistant. How can I assist you?"}]
data = {'type': type, 'scope': scope, 'chat_info': chat_info}
headers = {"Content-Type": "application/json"}
res = requests.post(url, headers=headers, json=json.dumps(data))
Cache-Querying
import json
import requests
url = 'http://127.0.0.1:5000/modelcache'
type = 'query'
scope = {"model": "CODEGPT-1008"}
query = [{"role": "system", "content": "You are an AI code assistant and you must provide neutral and harmless answers to help users solve code-related problems."}, {"role": "user", "content": "Who are you?"}]
data = {'type': type, 'scope': scope, 'query': query}
headers = {"Content-Type": "application/json"}
res = requests.post(url, headers=headers, json=json.dumps(data))
Cache-Clearing
import json
import requests
url = 'http://127.0.0.1:5000/modelcache'
type = 'remove'
scope = {"model": "CODEGPT-1008"}
remove_type = 'truncate_by_model'
data = {'type': type, 'scope': scope, 'remove_type': remove_type}
headers = {"Content-Type": "application/json"}
res = requests.post(url, headers=headers, json=json.dumps(data))
ModelCache 实际使用及问题解决
启动 demo
python flask4modelcache_demo.py
启动 falsk 服务,将 modelcache 部署在本地,通过 api 访问对应端口号进行通信。
测试服务,demo 中使用到的标量数据库为 sqlite,矢量数据库为 faiss
data_manager = get_data_manager(CacheBase("sqlite"), VectorBase("faiss", dimension=data2vec.dimension))
启动正式服务
python flask4modelcache.py
正式服务中,使用到的数据库可以自行配置,就使用默认的 Mysql 和 milvus
data_manager = get_data_manager(CacheBase("mysql", config=mysql_config),
VectorBase("milvus", dimension=data2vec.dimension, milvus_config=milvus_config))
流程解析
入口
后端 flask 服务 flask4modelcache.py
from modelcache import cache # 从core.py中导入cache定义
from modelcache.adapter import adapter # adapter LLM适配器
from modelcache.manager import CacheBase, VectorBase, get_data_manager # 数据库管理模块
from modelcache.similarity_evaluation.distance import SearchDistanceEvaluation # 相似度处理模块
from modelcache.processor.pre import query_multi_splicing # 工具函数
from modelcache.processor.pre import insert_multi_splicing # 工具函数
from concurrent.futures import ThreadPoolExecutor
from modelcache.utils.model_filter import model_blacklist_filter
from modelcache.embedding import Data2VecAudio # 字符串embedding
# 初始化
data2vec
mysql_config
milvus_config
data_manager = get_data_manager(CacheBase("mysql", config=mysql_config),
VectorBase("milvus", dimension=data2vec.dimension, milvus_config=milvus_config))
cache.init()
# 进行搜索,插入,删除
if request_type == 'query':
response = adapter.ChatCompletion.create_query(
scope={"model": model},
query=query
)
if request_type == 'insert':
response = adapter.ChatCompletion.create_insert(
model=model,
chat_info=chat_info
)
if request_type == 'remove':
response = adapter.ChatCompletion.create_remove(
model=model,
remove_type=remove_type,
id_list=id_list
)
适配器 Adapter
modelcache/adapter/adapter.py
负责调用查询,插入方法,提供对外接口
from modelcache.adapter.adapter_query import adapt_query
from modelcache.adapter.adapter_insert import adapt_insert
from modelcache.adapter.adapter_remove import adapt_remove
from modelcache.adapter.adapter_register import adapt_register
class ChatCompletion(openai.ChatCompletion):
def create_query(cls, *args, **kwargs):
return adapt_query(
cache_data_convert,
*args,
**kwargs
)
插入方法
modelcache/adapter/adapter_insert.py
插入逻辑实现,对句子进行 embedding。
随后通过调用 datamanager 的 save 方法对标量数据库和矢量数据库的插入。
def adapt_insert(*args, **kwargs):
cache_enable = chat_cache.cache_enable_func(*args, **kwargs)
context = kwargs.pop("cache_context", {})
embedding_data = None
system_sentence = [conv for conv in kwargs['chat_info'][0]['query'] if conv['role'] =='system']
kwargs2 = copy.deepcopy(kwargs)
kwargs2['chat_info'][0]['query'] = system_sentence
kwargs['chat_info'][0]['query'] = [conv for conv in kwargs['chat_info'][0]['query'] if conv['role'] != 'system']
pre_embedding_data = chat_cache.insert_pre_embedding_func(
kwargs,
extra_param=context.get("pre_embedding_func", None),
prompts=chat_cache.config.prompts,
)
sys_pre_embedding_data = chat_cache.insert_pre_embedding_func(
kwargs2,
extra_param=context.get("pre_embedding_func", None),
prompts=chat_cache.config.prompts,
)
chat_info = kwargs.pop("chat_info", [])
llm_data = chat_info[-1]['answer']
if cache_enable:
embedding_data = time_cal(
chat_cache.embedding_func,
func_name="embedding",
report_func=chat_cache.report.embedding,
)(pre_embedding_data)
sys_embedding_data = time_cal(
chat_cache.embedding_func,
func_name="embedding",
report_func=chat_cache.report.embedding,
)(sys_pre_embedding_data)
chat_cache.data_manager.save(
system_sentence,
sys_embedding_data,
pre_embedding_data,
llm_data,
embedding_data,
model=model,
extra_param=context.get("save_func", None)
)
return 'success'
数据库集成 data manager
modelcache/manager/data_manager.py
进行数据库相关操作的定义和处理
引入标量和向量数据库。 eviction_manager:缓存驱逐管理 此处进行数据的插入,删除,搜索
class SSDataManager(DataManager):
def __init__(
self,
s: CacheStorage,
v: VectorBase,
o: Optional[ObjectBase],
e: Optional[EvictionBase],
max_size,
clean_size,
policy="LRU",
):
self.max_size = max_size
self.clean_size = clean_size
self.s = s
self.v = v
self.o = o
self.eviction_manager = EvictionManager(self.s, self.v)
if e is None:
e = EvictionBase(name="memory",
maxsize=max_size,
clean_size=clean_size,
policy=policy,
on_evict=self._clear)
self.eviction_base = e
self.model = None
def import_data(
self, system_sentences:List[Any], sys_embedding_datas:List[Any], questions: List[Any], answers: List[Answer], embedding_datas: List[Any], model: Any
):
if len(questions) != len(answers) or len(questions) != len(embedding_datas):
raise ParamError("Make sure that all parameters have the same length")
cache_datas = []
embedding_datas = [
normalize(embedding_data) for embedding_data in embedding_datas
]
sys_embedding_datas = [
normalize(sys_embedding_data) for sys_embedding_data in sys_embedding_datas
]
for i, embedding_data in enumerate(embedding_datas):
if self.o is not None:
ans = self._process_answer_data(answers[i])
else:
ans = answers[i]
question = questions[i]
system_sentence = system_sentences[i][0]['content'].replace('"', "'")
embedding_data = embedding_data.astype("float32")
cache_datas.append([ans, system_sentence, question, embedding_data, model])
ids = self.s.batch_insert(cache_datas)
logging.info('ids: {}'.format(ids))
self.v.mul_add(
[
VectorData(id=ids[i], data=embedding_data,comment=system_sentences[i][0]['content'].replace('"', "'"))
for i, embedding_data in enumerate(embedding_datas)
],
model
)
self.eviction_base.put(ids)
def search(self, system_sentence, embedding_data, **kwargs):
model = kwargs.pop("model", None)
embedding_data = normalize(embedding_data)
top_k = kwargs.get("top_k", -1)
return self.v.search(sys_sentence =system_sentence, data=embedding_data, top_k=top_k, model=model) # 查找操作
def delete(self, id_list, **kwargs):
model = kwargs.pop("model", None)
try:
v_delete_count = self.v.delete(ids=id_list, model=model)
except Exception as e:
return {'status': 'failed', 'milvus': 'delete milvus data failed, please check! e: {}'.format(e),
'mysql': 'unexecuted'}
try:
s_delete_count = self.s.mark_deleted(id_list)
except Exception as e:
return {'status': 'failed', 'milvus': 'success',
'mysql': 'delete mysql data failed, please check! e: {}'.format(e)}
return {'status': 'success', 'milvus': 'delete_count: '+str(v_delete_count),
'mysql': 'delete_count: '+ str(s_delete_count)}
data manager 调用具体的数据库操作 py 文件完成对标量/矢量数据库的操作
具体数据库操作
mysql:
modelcache/manager/scalar_data/sql_storage.py
class SQLStorage(CacheStorage):
def __init__(
self,
db_type: str = "mysql",
config=None
):
self.host = config.get('mysql', 'host')
self.port = int(config.get('mysql', 'port'))
self.username = config.get('mysql', 'username')
self.password = config.get('mysql', 'password')
self.database = config.get('mysql', 'database')
self.pool = PooledDB(
creator=pymysql,
host=self.host,
user=self.username,
password=self.password,
port=self.port,
database=self.database
)
Milvus 默认索引配置为:
MILVUS_INDEX_PARAMS = {
"metric_type": "L2",
"index_type": "HNSW",
"params": {"M": 8, "efConstruction": 64},
}
Milvus 数据库相关操作如下:
class Milvus(VectorBase):
SEARCH_PARAM = {
"IVF_FLAT": {"metric_type": "L2", "params": {"nprobe": 10}},
"IVF_SQ8": {"metric_type": "L2", "params": {"nprobe": 10}},
"IVF_PQ": {"metric_type": "L2", "params": {"nprobe": 10}},
"HNSW": {"metric_type": "L2", "params": {"ef": 10}},
"RHNSW_FLAT": {"metric_type": "L2", "params": {"ef": 10}},
"RHNSW_SQ": {"metric_type": "L2", "params": {"ef": 10}},
"RHNSW_PQ": {"metric_type": "L2", "params": {"ef": 10}},
"IVF_HNSW": {"metric_type": "L2", "params": {"nprobe": 10, "ef": 10}},
"ANNOY": {"metric_type": "L2", "params": {"search_k": 10}},
"AUTOINDEX": {"metric_type": "L2", "params": {}},
}
def __init__(
self,
host: str = "localhost",
port: str = "19530",
user: str = "",
password: str = "",
secure: bool = False,
collection_name: str = "modelcache",
dimension: int = 0,
top_k: int = 1,
index_params: dict = None,
search_params: dict = None,
local_mode: bool = False,
local_data: str = "./milvus_data"
):
if dimension <= 0:
raise ValueError(
f"invalid `dim` param: {dimension} in the Milvus vector store."
)
self._local_mode = local_mode
self._local_data = local_data
self.dimension = dimension
self.top_k = top_k
self.index_params = index_params
if self._local_mode:
self._create_local(port, local_data)
self._connect(host, port, user, password, secure)
self.collection_name = collection_name
self.search_params = (
search_params or self.SEARCH_PARAM[self.index_params["index_type"]]
)
缓存驱逐策略
在 SSDataManager 类中,设置了 max_size 和 clean_size,以及缓存驱逐策略 policy=LRU。
class SSDataManager(DataManager):
def __init__(
self,
s: CacheStorage,
v: VectorBase,
o: Optional[ObjectBase],
e: Optional[EvictionBase],
max_size,
clean_size,
policy="LRU",
):
self.max_size = max_size
self.clean_size = clean_size
self.s = s
self.v = v
self.o = o
self.eviction_manager = EvictionManager(self.s, self.v)
if e is None:
e = EvictionBase(name="memory",
maxsize=max_size,
clean_size=clean_size,
policy=policy,
on_evict=self._clear)
self.eviction_base = e
def _clear(self, marked_keys):
self.eviction_manager.soft_evict(marked_keys)
在进行 insert 时,调用 data manager 中的 save 函数,调用 self.import_data 函数 ,
def import_data(
self, system_sentences:List[Any], sys_embedding_datas:List[Any], questions: List[Any], answers: List[Answer], embedding_datas: List[Any], model: Any
):
if len(questions) != len(answers) or len(questions) != len(embedding_datas):
raise ParamError("Make sure that all parameters have the same length")
cache_datas = []
embedding_datas = [
normalize(embedding_data) for embedding_data in embedding_datas
]
sys_embedding_datas = [
normalize(sys_embedding_data) for sys_embedding_data in sys_embedding_datas
]
for i, embedding_data in enumerate(embedding_datas):
if self.o is not None:
ans = self._process_answer_data(answers[i])
else:
ans = answers[i]
question = questions[i]
system_sentence = system_sentences[i][0]['content'].replace('"', "'")
embedding_data = embedding_data.astype("float32")
cache_datas.append([ans, system_sentence, question, embedding_data, model])
ids = self.s.batch_insert(cache_datas)
logging.info('ids: {}'.format(ids))
self.v.mul_add(
[
VectorData(id=ids[i], data=embedding_data,comment=system_sentences[i][0]['content'].replace('"', "'"))
for i, embedding_data in enumerate(embedding_datas)
],
model
)
self.eviction_base.put(ids)
导入数据最后向缓存驱逐策略存入对应 id
self.eviction_base.put(ids)
eviction_base 的实现为:
e = EvictionBase(name="memory",
maxsize=max_size,
clean_size=clean_size,
policy=policy,
on_evict=self._clear)
self.eviction_base = e
EvictionBase 类返回了一个 eviction_base = MemoryCacheEviction(policy, maxsize, clean_size, on_evict, **kwargs)
MemoryCacheEviction 类在 modelcache\manager\eviction\memory_cache.py 中具体定义:
from typing import Any, Callable, List
import cachetools
from modelcache.manager.eviction.base import EvictionBase
def popitem_wrapper(func, wrapper_func, clean_size):
"""
生成一个包装函数来处理popitem操作的缓存清理
参数:
func: 原始的popitem操作函数
wrapper_func: 用于处理清理操作的外部函数
clean_size: 每次清理的大小
返回:
包装后的popitem操作函数
"""
def wrapper(*args, **kwargs):
keys = []
try:
keys = [func(*args, **kwargs)[0] for _ in range(clean_size)]
except KeyError:
pass
wrapper_func(keys)
print("clear cache!!")
return wrapper
class MemoryCacheEviction(EvictionBase):
def __init__(self, policy: str, maxsize: int, clean_size: int, on_evict: Callable[[List[Any]], None], **kwargs):
"""
初始化MemoryCacheEviction对象。
Args:
policy (str): 缓存策略,支持"LRU"、"LFU"、"FIFO"和"RR"。
maxsize (int): 缓存的最大大小。
clean_size (int): 在触发清理操作时,一次清理的数量。
on_evict (Callable[[List[Any]], None]): 缓存清理时的回调函数。
kwargs: 其他参数。
"""
self._policy = policy.upper()
if self._policy == "LRU":
self._cache = cachetools.LRUCache(maxsize=maxsize, **kwargs)
elif self._policy == "LFU":
self._cache = cachetools.LFUCache(maxsize=maxsize, **kwargs)
elif self._policy == "FIFO":
self._cache = cachetools.FIFOCache(maxsize=maxsize, **kwargs)
elif self._policy == "RR":
self._cache = cachetools.RRCache(maxsize=maxsize, **kwargs)
else:
raise ValueError(f"Unknown policy {policy}")
self._cache.popitem = popitem_wrapper(self._cache.popitem, on_evict, clean_size)
def put(self, objs: List[Any]):
"""
将多个对象添加到缓存中。
Args:
objs (List[Any]): 要添加到缓存的对象列表。
"""
for obj in objs:
self._cache[obj] = True
当上文存入 ids 时调用 put 方法,put 方法将 self._cache 对应 ids 位置标记为已存储。
self._cache 的实现在 MemoryCacheEviction 类的 init 方法中,其中,on_evict 参数定义了缓存清理时的回调函数。
让我们回顾在定义驱逐缓存类时传入的 on_evict 参数:
实际上是调用了 SSDatamanager 的 self._clear 函数:
def _clear(self, marked_keys):
self.eviction_manager.soft_evict(marked_keys)
if self.eviction_manager.check_evict():
self.eviction_manager.delete(self.model)
对要删除的数据进行软删除。当软删除的数据量达到一定规模时,对数据库进行实际的删除操作。 检查方法如下:
def check_evict(self):
# 检查是否需要驱逐数据
mark_count = self._scalar_storage.count(state=1) # 获取标记为删除的数据数量
all_count = self._scalar_storage.count(is_all=True) # 获取所有数据的数量
if (
mark_count > self.MAX_MARK_COUNT # 如果标记为删除的数据数量超过最大标记数量
or mark_count / all_count > self.MAX_MARK_RATE # 或者标记为删除的数据数量占所有数据的比例超过最大标记比例
):
return True # 需要驱逐数据
return False # 不需要驱逐数据
开源项目贡献和相关问题
下述提到的问题均已提交 PR,已经合入,在后续使用中不会再出现。
demo 中 clear 方法无法清除 faiss 索引信息
详见 PR35
在使用 Cache-Clearing 方法时,无法清除 faiss 的索引信息,并返回错误消息。
查看其源码,modelcache/manager/vector_data/faiss.py
发现清除索引时调用的方法直接返回 True,并未实现,修改后实现如下:

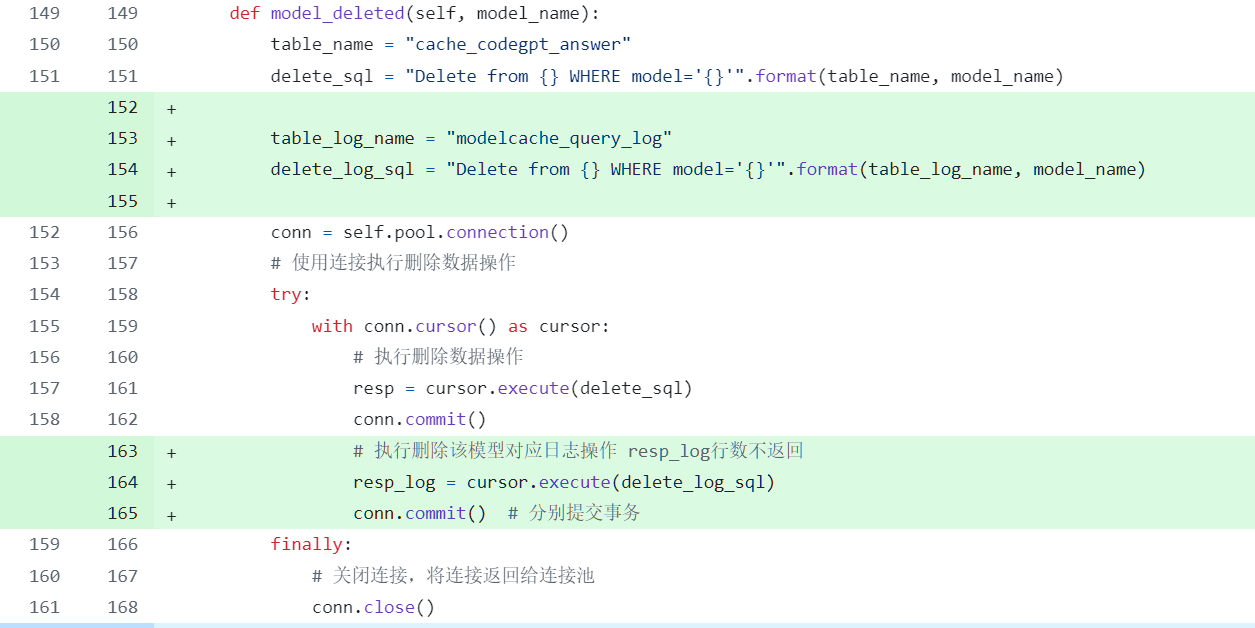
clear 方法无法清除日志信息
详见 PR40
ModelCache 会创建几个表,包括 cache_codegpt_answer,记录 llm 返回的结果,modelcache_query_log 日志表,记录查询的日志。
在使用 Cache-Clearing 方法时,只清除了 cache_codegpt_answer,并未清除 log 日志表。 在实际使用中,通常希望保留log日志以便追溯,但没有清除方法会导致log无限制地增长。经讨论可在开源项目中添加清除操作。
在标量数据库实现方法中添加清除 log 日志表的操作;
modelcache/manager/scalar_data/sql_storage.py
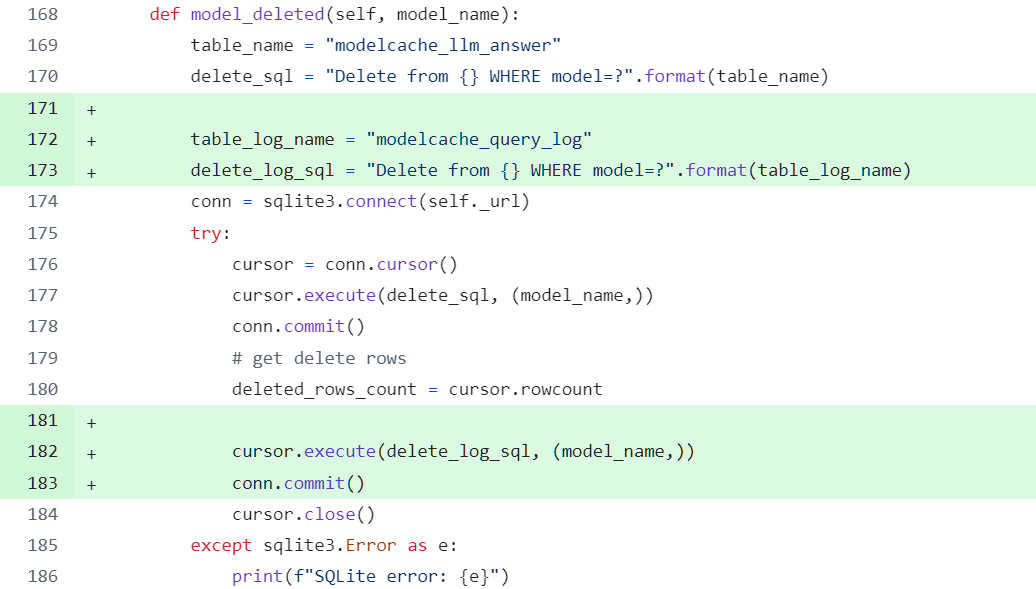
在前面的 demo 中同样存在这个问题:
modelcache/manager/scalar_data/sql_storage_sqlite.py
缓存驱逐策略相关问题
详见 PR44
ModelCache 可以设定缓存数据库的大小,当缓存条目数量达到设定大小时,应该使用缓存驱逐策略对数据库中的内容进行选择性删除。
- 缓存驱逐的大小:每次运行清空,重新读取
- 缓存策略:LRU
- 缓存参数,可指定。
- 每次插入数据时,当数据量超过设定数量,触发
_clear函数, mark 要删除数据,当 mark 的数据达到设定值 (占比 0.1 或绝对值 5000),触发硬删除。modelcache/manager/eviction_manager.py
class EvictionManager:
MAX_MARK_COUNT = 5000 # 最大标记数量
MAX_MARK_RATE = 0.1 # 最大标记比例
BATCH_SIZE = 100000 # 批处理大小
REBUILD_CONDITION = 5 # 重建条件
遇到的问题:
1.由于多个方法未实现,在应用缓存驱逐策略时问题较多。
2.mark_deleted 并未进行软删除,而是直接删除 mark_id 的数据。
3.数据库中 cache_codegpt_answer 表并没有 is_deleted 字段,无法执行软删除。
4.给出的建表语句中,modelcache_llm_answer 只在 sqlite 中应用,而在使用 mysql 时,使用的却是 cache_codegpt_answer 表。
5.self._vector_base.delete 方法未给出 model,导致缓存驱逐时无法删除对应表。
修改方法:
1.软删除改为真正的软删除:
数据库中表,改名,添加字段。
modelcache\manager\scalar_data\sql_storage.py 文件中:
mark_deleted 方法的实现,标记 is_deleted 字段为 1(待删除)
clear_deleted_data 方法的实现
count 方法的实现
2.数据库修改,
(1) 将 reference_doc\create_table.sql 中的表名从 modelcache_llm_answer 改成 cache_codegpt_answer,当然也可以修改代码中的 table_name。
(2) cache_codegpt_answer 中添加 is_deleted 字段,-1 为待删除,0 为不删除,(与 gptcache 一致)。
3.缓存驱逐策略的实现,默认 lru。
modelcache\manager\eviction_manager.py 中,
delete 方法加入参数 model,以便在 milvus 中进行删除对应的 ids 记录
直接在 data_manager.py 中应用缓存驱逐策略。
要直接在 data_manager.py 运用缓存驱逐策略(mysql+milvus),在 Fix cache eviction and soft deleted using MySQL and milvus by powerli2002 · Pull Request #44 · codefuse-ai/ModelCache 这个 PR 的基础上,还需在 modelcache\manager\data_manager.py 添加 :
class SSDataManager(DataManager):
def __init__(
self,
s: CacheStorage,
v: VectorBase,
o: Optional[ObjectBase],
e: Optional[EvictionBase],
max_size,
clean_size,
policy="LRU",
):
self.max_size = max_size
self.clean_size = clean_size
self.s = s
self.v = v
self.o = o
self.eviction_manager = EvictionManager(self.s, self.v)
if e is None:
e = EvictionBase(name="memory",
maxsize=max_size,
clean_size=clean_size,
policy=policy,
on_evict=self._clear)
self.eviction_base = e
self.model = None
def _clear(self, marked_keys):
self.eviction_manager.soft_evict(marked_keys)
# soft直接删除了
if self.eviction_manager.check_evict():
self.eviction_manager.delete(self.model)
def save(self, system_sentence, sys_embedding_data,question, answer, embedding_data, **kwargs):
self.model = kwargs.pop("model", None)
self.import_data([system_sentence], [sys_embedding_data], [question], [answer], [embedding_data], self.model)
self.model 的定义是为了在插入的时候告诉 data manager 现在正在处理哪一个模型的表。
添加 Chroma 存储功能
详见 PR60
Chroma 是一种向量数据库,gptcache 的 chroma 设置创建方式已经过时: 现在不支持直接传入 settings
class Chromadb(VectorBase):
def __init__(
self,
persist_directory="./chromadb",
top_k: int = 1,
):
self.collection_name = "modelcache"
self.top_k = top_k
self._client = chromadb.PersistentClient(path=persist_directory)
self._collection = None
另外,对于 mm,向量数据库中,每个类型数据存储到单独的 collection 中
在 pr 中的 chromadb 实现,是使用 chromadb.PersistentClient 方法将其持久化本地。官方文档中说这不是适用于生产环境的方法。如果更改为 HttpClient,或 AsyncHttpClient,则需要提前运行 chroma run --path /db_path 命令,可能需要在 readme 文档中说明。
我发现在 multicache 中有一些矛盾,例如:
- 针对向量数据库,redis 的实现逻辑是,不同类型的数据存到不同的 index 中,而在 faiss 中则没有这个逻辑。
- 多个方法名与 非多模态的 modelcache 对应的向量数据库方法 不一致。例如重建数据库,多模态方法:
def rebuild_idx(self, model):, 非多模态方法:def rebuild_col(self, model): - 在多模态的 redis 实现逻辑中,几乎所有方法都使用了参数
mm_type,然而在调用这些方法时,有些情况没有传入该参数,例如add,delete等。但是基于存储数据的需要,我仍然选择将数据存入不同的 collection 中。 - 此外,可能有部分软件包没有列入到 requirements.txt 中。
添加 es 存储功能
详见 PR59
实现了 ModelCache 对 Elasticsearch 作为标量数据库的支持。
ES 主键问题
uuid,雪花 id 优缺点分析: Leaf——美团点评分布式ID生成系统 - 美团技术团队
es 使用自动生成的 uuid 作为 _id 主键, 而项目中的 milvus 处理中,使用 INT64 接收参数。
需要寻找 es 主键的替代生成方式,又要避免并发性问题
使用 pip install snowflake-id 库来生成雪花算法 id
PYPI 官方文档:
雪花 ID · PyPI — snowflake-id · PyPI
from snowflake import SnowflakeGenerator
gen = SnowflakeGenerator(42) # instance实例id
for i in range(100):
val = next(gen)
print(val)
雪花 id 整体按照时间自增排序,并且正确配置机器 id 不会在系统内产生 id 碰撞。
使用时间
插入 100 条数据 使用雪花 id 的 ES : time used: 90.17902493476868 不使用雪花 id 的 ES:time used: 65.81654500961304 Mysql:time used: 31.118371963500977
noitce
1.ES 主键问题
由于 es 使用自动生成的 uuid 作为 _id 主键, 而项目中向量数据库(例如 Milvus)处理中,使用 INT64 接收参数。
使用雪花 id 替代 es 生成的 uuid,使用到 snowflake-id 库。
雪花 id 的生成与时间戳,机器分配的标识(代码中取 1),且支持同一节点同一毫秒生成多个 ID,12 个 bit 支持每个节点每 ms 生成 4096 个 id。雪花 id 整体按照时间自增排序,正确配置机器标识不会在系统内产生 id 碰撞。
缺点:
(1) 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复。
(2) 时间开销较大。
插入 100 条数据,向量数据库使用 Milvus
使用雪花 id 的 ES : time used: 90.179
不使用雪花 id 的 ES:time used: 65.817
Mysql:time used: 31.118